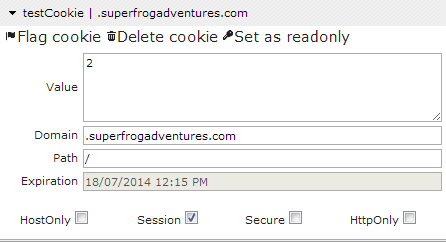
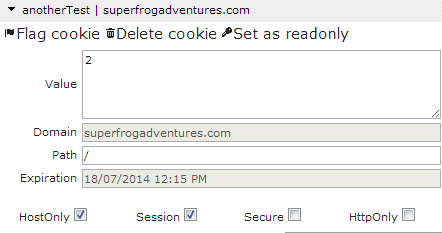
I’ve recently begun working with Angular and by extension Angular UI-Router. The fact that you are reading this means that you likely have as well. That said, let’s all pause for a moment and cry together. I know it’s hard. You will get through it. It will be ok. We can do this.
Basic ui-sref-active Usage
One of the things that UI-Router gives you is the ability to add a class to an element if that elements state is currently active. This is done via the ui-sref-active directive.
<ul class="nav navbar-nav" ng-controller="navController"> <li class="nav-node nav" ui-sref-active="active"><a ui-sref="home">Home</a></li> <li class="nav-node nav" ui-sref-active="active"><a ui-sref="notHome">Not Home</a></li> </ul>
So above we have some basic navigation with two states. The home state and the notHome state. The ui-sref-active directive takes care of adding the active class to whichever li contains the state that is currently active.
The Problem with Abstract States
The problem is that the ui-sref-active directive does not work correctly (or as we expect) when the parent state is an abstract state.
Let’s say you want to expand your “home” state a bit. Maybe you want to add a “dashboard” state and from there link to a “messages” state. You might set up your $stateProvider a bit like this.
$stateProvider
.state("home",
{
abstract: true,
url: "/home"
})
.state("home.dashboard", {
url: "/dashboard",
views: {
"content@": {
templateUrl: "app/home/dashboard.html",
controller: "DashboardController"
}
}
})
.state("home.messages", {
url: "/messages",
views: {
"content@": {
templateUrl: "app/home/messages.html",
controller: "MessagesController"
}
}
});
You’ll see we’ve setup home as an abstract view. By default we want to land on our home.dashboard state. We also want ui-sref-active to set the active class on our “Home” link regardless of which child state we are on.
<ul class="nav navbar-nav" ng-controller="navController"> <li class="nav-node nav" ui-sref-active="active"><a ui-sref="home.dashboard">Home</a></li> <li class="nav-node nav" ui-sref-active="active"><a ui-sref="notHome">Not Home</a></li> </ul>
You will notice that in the code above we are now using ui-sref to link to home.dashboard. This is where the problem with ui-sref-active crops up, it will only show the active class if the state is home.dashboard. We want the active class to appear on any child of the “home” state. As it is, the ui-sref-active directive will not detect home.messages as active. So the question becomes, “how can we fix ui-sref-active so that it detects a parent abstract state”?
Fixing ui-sref-active
The answer comes from Tom Grant in the form of a comment on a GitHub issue.
Tom informs us that there is an undocumented built in solution to this ui-sref-active problem. The solution, he says, is to “use an object (like with ng-class) and it will work”.
Code examples that Tom provides:
<!-- This will not work -->
<li ui-sref-active="active">
<a ui-sref="admin.users">Administration Panel</a>
</li>
<!-- This will work -->
<li ui-sref-active="{ 'active': 'admin' }">
<a ui-sref="admin.users">Administration Panel</a>
</li>
That’s it. Now we can link to children of abstract ui-router states and ui-sref-active will behave the way we expect it should.