I’m adding a simple post here with a PHP method that has helped me. This method calculates the beginning and ending of a week given the year and week number. The problem I’ve run into is that “first day of the week” is subjective. Some people believe the first day of the week is “Monday” while others believe the first day of the week is “Sunday”. ISO-8601 specifies the first day of the week as “Monday”. Whereas, most western calendars display Sunday as the first day of the week and Saturday as the last day of the week.
To add to the confusion, PHP’s methods themselves seem confused about what the first and last day of the week are.
For example:
$new_date = new DateTime;
// returns Monday, Jan 29 2018
$new_date->setISODate(2018, 5);
// returns Sunday, Feb 4 2018
$new_date->modify('sunday this week');
// returns Sunday, Jan 28 2018
$new_date->setISODate(2018, 5 ,0);
You’ll notice that the string “sunday this week” actually returns Sunday, Feb 4 whereas setting the date to the 0 day of the same week returns Sunday, Jan 28. I’m not saying that Sunday doesn’t happen twice a week… but Sunday doesn’t happen twice a week.
All this to say, the method below is the one I’ve found returns the most helpful results:
function get_first_and_last_day_of_week( $year_number, $week_number ) {
// we need to specify 'today' otherwise datetime constructor uses 'now' which includes current time
$today = new DateTime( 'today' );
return (object) [
'first_day' => clone $today->setISODate( $year_number, $week_number, 0 ),
'last_day' => clone $today->setISODate( $year_number, $week_number, 6 )
];
}
Every once and a while I want to validate the hash of a downloaded file. Most of the time these are MD5 hashes, but I’ve seen SHA as well.
Windows actually has a couple built in ways of generating the hash of a file. You can use certutil or, in powershell you can use get-filehash.
With Certutil
To verify a checksum with certutil use the following command: certutil -hashfile {FILENAME} {ALGORITHM} replace the FILENAME and ALGORITHM with your choices.
With get-filehash
This is my preferred method. No reason, maybe I like the order of arguments better?
Use get-filehash -algorithm {ALGORITHM} {FILENAME}.
First things first, I tend to build up a lot of local branches. No, I don’t pro-actively remove them from my machine. (Who does that extremely smart thing? ?) At work we use GitHub and Windows. As such I use posh-git to perform almost all my git interactions (you should too cause it’s ?).
Our current process is:
Create Feature Branch
Create Pull Request
Squash and Merge Pull Request
Delete Feature Branch from Remote
Any developer can have any number of feature branches out at a time waiting to be merged. As we are using a “Squash and Merge” process our branches are not *actually merged*. We delete the original branch after the squash.
But that doesn’t really matter to you. Come to think of it, it doesn’t really matter to future me. What does matter is, how can I remove local git branches that aren’t on the git remote anymore? (Remote meaning GitHub, Gitlab, Bitbucket, etc…). No, we aren’t talking about the remote tracking branches that are removed by pruning. Otherwise, one could just prune, no?
I continuously search for this, so I’m documenting it here so I NEVER HAVE TO SEARCH EVER AGAIN ?
If you are in a position where you Squash & Merge then you will need to replace the git branch -d with git branch -D. This will successfully remove all “:gone” branches from your local machine.
Any git branch you have checked out essentially has three branches. 1. The remote branch on GitHub 2. The remote tracking branch on your machine 3. The local branch you do your work on.
When we push a feature branch live (merge a pull request) we delete the “remote branch on GitHub” (#1 above).
When we run `git fetch origin –prune` we remove the remote tracking branch (taking care of #2) above.
However, taking care of #3 above often requires manual clean up. That’s where the piped command above comes into play, it takes care of cleaning up branch #3.
I find it extremely useful to include surrounding lines when I’m searching through log files or whatnot for a string of text. It certainly helps provide some context as to what I’m looking at.
However, I constantly forget the flag for including surrounding lines. So I’m posting it here so that, at least when I forget, I know where to find it ?
The flag is -C. I suppose it should be easy to remember since I want “Context” and “Context” begins with “C”. ?
Below is a quick example for just in case you want the whole command or you enjoy copying and pasting all the things – hey… no judgement here.
I just recently got Visual Studio Code hooked up with the virtual Vagrant machine hosting my local dev version of WordPress. I’m posting the steps I took here. In the end it’s fairly simple to do.
Most of the guides out there show you how to hook up VS Code with a locally running copy of WordPress. However, I’m using Chassis.io for my dev version of WordPress. Chassis.io makes use of Vagrant and a virtual machine. I did not find anything that showed me how to hook VS Code with a copy of WordPress running on a virtual machine, as is the case with a Chassis.io setup.
Setup Chassis for Debugging with Visual Studio Code
The first thing we need to do to setup the Chassis XDebug extension to work with Visual Studio Code is to setup the IDE Key. Setting up the IDE Key consists of two steps.
Bring up the XDebug Helper extension options page. You can do this by Right Clicking the extension icon and selecting Options.
XDebug Extension Options
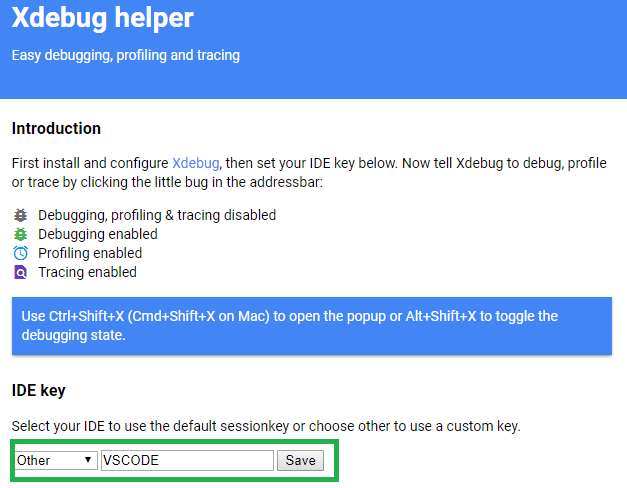
Find the section for the IDE Key. Select Other as the default sessionkey and type in VSCODE.
XDebug Extension IDE Key Setting
Save it. Next we need to set the IDE Key for the Vagrant machine.
Set the IDE Key for the Vagrant Machine
This step is pretty simple. First you need to navigate to the root Chassis directory. Mine is located at C:\projects\chassis.
Create a config.local.yaml file if one doesn’t already exist.
Add ide: VSCODE to the config.local.yaml file.
Run vagrant provision which should update the settings on your local vagrant machine.
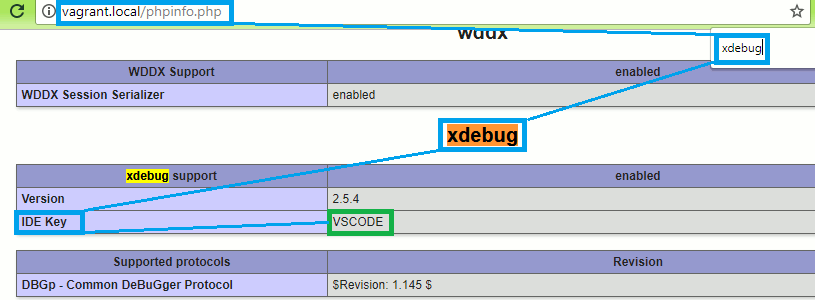
To confirm that the IDE Key is indeed VSCODE see the “xdebug” section on the PHPInfo page for the machine.
Example: http://vagrant.local/phpinfo.php
xdebug section on the PHP Info page
Setup Visual Studio Code for Debugging with Chassis
If you are using Visual Studio Code to develop PHP than you should install the PHP Extension Pack. Bring up the VS Code Extensions menu and search for “PHP Extension Pack”. This extension will include the PHP Intellisense plugin and the PHP Debugger plugin. You will need the PHP Debugger plugin for debugging.
Next we need to setup a debugging configuration.
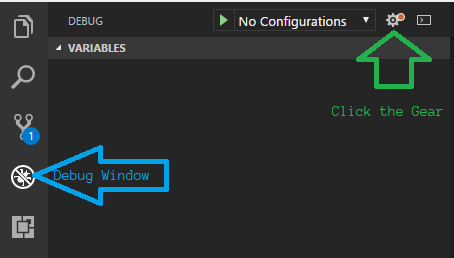
Click the Gear to setup a Debugging configuration.
Bring up the VS Code debugging window.
Click the “Gear” icon.
Select “PHP” as your environment from the popup textbox.
Now you will see a “launch.json” file in your VS Code window. This contains some default settings for debugging PHP. The file will not work for our purposes as it is. We need to add a couple properties to the JSON to hook VS Code up with our WordPress site.
serverSourceRoot – This is the directory for your code on the server (Chassis.io).
localSourceRoot – This is the directory for your code on your development machine.
The serverSourceRoot needs to be the path to your source code on the server. In my case the value is /vagrant/content/plugins/my-awesome-plugin.
The localSourceRoot is used to match the server source up with your local source. In my case I set this to ${workspaceRoot} which is a special variable referring to the path of the opened folder in VS Code.
Alright! That should be it. Save your launch.json file, set a breakpoint in your code, and start the debugger. When you visit the relevant WordPress page on your Chassis box you will notice your breakpoint is hit.
Chassis.io is an excellent tool to get you quickly setup for WordPress development. Barring any timeout issues, the setup is typically as simple as following their QuickStart guide.
Chassis.io uses Vagrant and VirtualBox to setup a Virtual Machine that hosts your WordPress site. This post covers how you can connect to your WordPress database that exists on that Virtual Machine. I’ll be using Windows and HeidiSQL for the purpose of this post. The connection information I use in this post comes from this GitHub issue.
Connecting with HeidiSQL
HeidiSQL is my favorite query browser for MySQL and MariaDB databases. I like the layout and the interface is nice and clean.
When you first open HeidiSQL you will see the interface for creating a new Database connection.
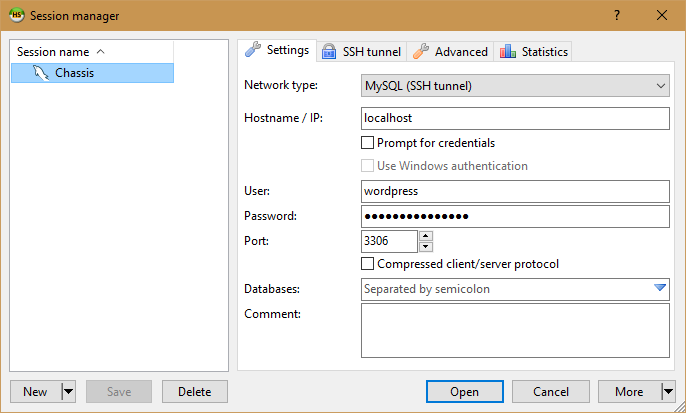
Choose whichever name you want to help you remember what this connection is for. I’ve named mine “Chassis” because it’s my connection to the database Chassis.io setup. You’ll also want to set the following settings:
Network type: MySQL (SSH tunnel)
Hostname / IP: localhost
User: wordpress
Password: vagrantpassword
Port: 3306
That’s it for the basic settings. Now for the SSH Tunnel settings.
HeidiSQL – Plink.exe and Private Key
HeidiSQL uses a utility called “plink.exe” for it’s SSH capabilities. plink.exe is made by the same author who wrote PuTTY (which I’m sure you’ve heard of). If you haven’t got plink.exe downloaded you can find the latest exe on this page. You’ll want to grab both plink.exe and puttygen.exe. I stuck both utilities inside a “PuTTY” folder in my Program Files (x86) directory. You can stick them wherever you want to.
Ok, before we setup the SSH Tunnel settings we are going to want to setup the Private key file that plink.exe will use to communicate with your Virtual Machine. PuTTY utilities use specific private key files called .ppk files. We are going to want to convert the Vagrant provided private key file to a .ppk file for use by plink.exe. Luckily, the puttygen.exe utility you downloaded makes this conversion simple.
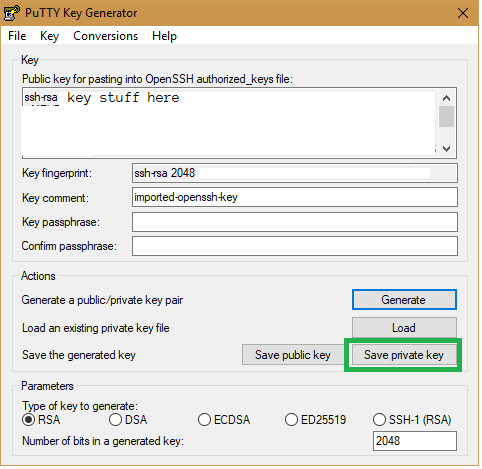
Launch puttygen.exe. This will launch the “PuTTY Key Generator”. Load in the Vagrant provided private key file by using File > Load Private Key. Navigate to the location of your Vagrant private key file. Mine was located in C:\projects\chassis\.vagrant\machines\default\virtualbox. Your location may be different depending on where your Chassis project is. Find the “private_key” file and open that. The PuTTY Key Generator will take care of loading the key in for you. You should see a “Successfully imported foreign key …” message. Now click “Save private key”, choose a name for it, and save it. I just saved it exactly where the other private_key was.
Location of the “Save private key” button
Woot! Now we can fill out the HeidiSQL SSH tunnel settings. Remember where you saved that .ppk file because you’ll need it for this next step.
HeidiSQL – SSH Tunnel Settings
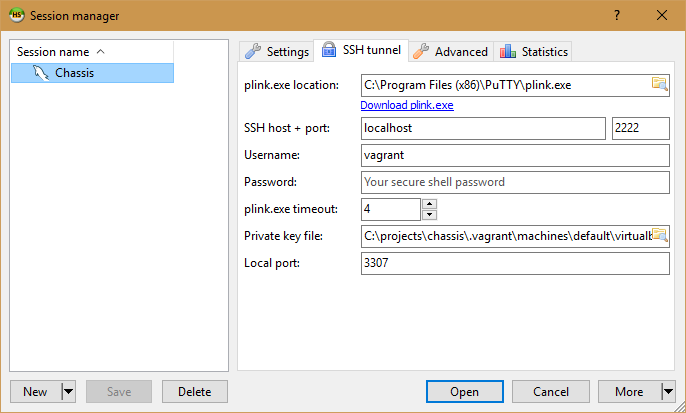
Click on the tab for “SSH tunnel” to access the HeidiSQL Session Manager SSH Tunnel settings.
HeidiSQL SSH Tunnel Settings
Alright, let’s plug in the values!
plink.exe location: Insert the path to your plink.exe utility.
SSH host + port: localhost and 2222
Username: vagrant
Password: just leave this blank
plink.exe timeout: default is fine
Private key file: Path to the .ppk file we created above
Local port: 3307 is fine
Now we come to the moment of truth. Push the “Save” button on the HeidiSQL session manager to save your changes. Now push the “Open” button and HeidiSQL should connect to your Vagrant hosted WordPress database. Woot!
TL:DR -> Try enabling Virtualization in your BIOS.
I’m trying out http://chassis.io as a way to easily setup a WordPress development environment on Windows. It’s actually quite easy and everything works almost exactly like the Chassis Get Started guide describes.
However, I ran into a timeout issue when attempting to boot up the Virtual Machine using vagrant up. On first run the process installed necessary dependencies and wired most things up. However, it hung for a considerable amount of time when booting up the virtual machine. Eventually it told me that it had timed out. It didn’t start the virtual machine.
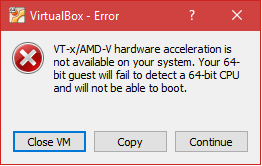
VT-x/AMD-V hardware acceleration is not available on your system
Hrmm… I wonder why it’s timing out. Chassis.io uses Vagrant and VirtualBox. So I spun up VirtualBox to see if I could manually start the VM myself. As it turns out, I could not. VirtualBox threw up the following error:
VT-x/AMD-V hardware acceleration is not available on your system. Your 64-bit guest will fail to detect a 64-bit CPU and will not be able to boot.
Well, that’s nice… (Hint: it’s not nice).
First Try: Disabling Hyper-V
I did some searching. I found a number of posts that indicated the solution was to disable Hyper-V. It sounds like this works for a lot of people. Scott Hanselman actually wrote up a post about how to “Switch easily between VirtualBox and Hyper-V with a BCDEdit boot Entry in Windows 8.1“. I tried this approach. It did not work for me (you can remove a bcdEdit entry using bcdedit /delete {ENTRYGUID} btw).
Second Try: Enabling Virtualization via BIOS
During my search I stumbled upon this SuperUser answer. The answer indicated that, depending on your system, Virtualization could be enabled via the BIOS.
In my case, enabling Virtualization via BIOS involved booting to the UEFI Firmware Settings. I’ve outlined the steps below.
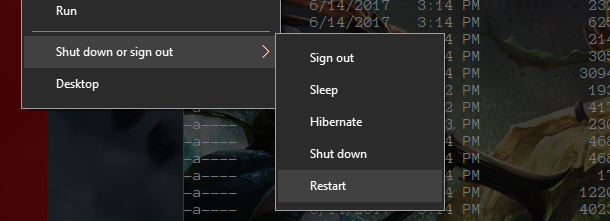
Hold down the Shift key while you click Restart. This will cause your computer to bring up a special menu.
Hold down “SHIFT” and click Restart
Next you need to navigate the option screens to find “UEFI Firmware Settings”
1. Select “Troubleshoot”
2. Select “Advanced options”
3. Select “UEFI Firmware Settings”
4. Restart
Steps to UEFI Firmware Settings
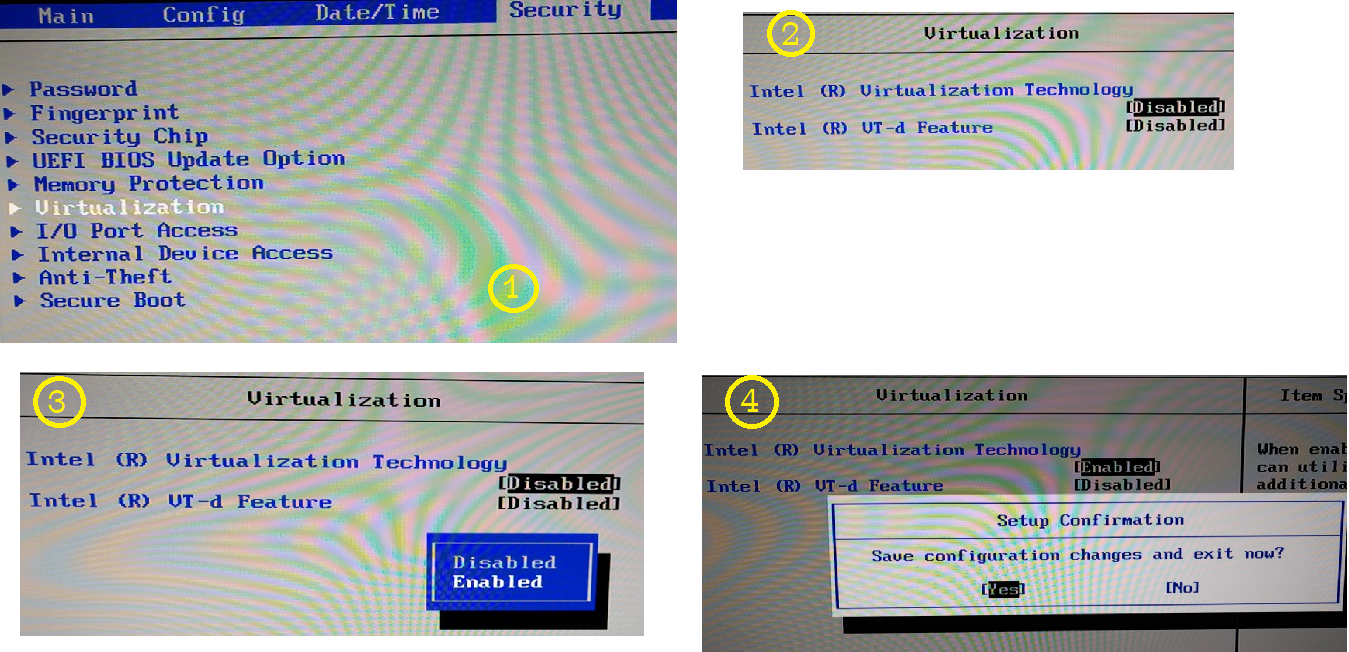
This will reboot you into your PC’s UEFI settings which looks a lot like a typical BIOS menu.
Enable Virtualization
Your system may be different. My system had a “Virtualization” setting located under the “Security” tab. Once I located the “Virtualization” setting I noticed that “Intel (R) Virtualization Technology” was indeed set to Disabled. I enabled it, saved the setting, and restarted my machine.
Enable Virtualization via BIOS
After enabling “Virtualization” I tried to start the VirtualBox VM one more time. BOOM. It worked. I ran vagrant up via a ConEmu console and… success.
In Conclusion
Chassis.io is a pretty sweet project. If your system is setup correctly then Chassis.io “just works”. In my case my system needed “Virtualization” enabled via a UEFI Firmware Setting.
Recently I made the switch from using Visual Studio 2015 to using Visual Studio 2017. For the most part the transition was easy. However, I ran into an issue with Entity Framework updating the wrong database. I’m posting the solution here so I don’t forget 🙂
TL:DR
If you are experiencing issues with Entity Framework then check that your startup project is the correct one.
EF Update-Database Is Not Working
My current setup involves using a local SQL Server Express database. I check the database via SQL Server Management Studio (ManStu) when I run Update-Database to ensure my changes take place. When I run Update-Database from Visual Studio 2015 the changes are reflected in the database. When I run Update-Database from Visual Studio 2017 the changes are not reflected in the database.
Why does Update-Database work correctly in Visual Studio 2015 but not correctly in Visual Studio 2017? Why does Visual Studio 2017 tell me that the changes were applied successfully?
I decided to take a look at the output of Update-Database -Verbose to see if it yielded any helpful information. There I saw:
Target database is: 'MySpecialDB' (DataSource: (localdb)\v11.0, Provider: System.Data.SqlClient, Origin: Convention).
Entity Framework was using (localdb) and not the SQL Server Express database I setup in the app.config. That explains why the changes were applied successfully. However, why was Entity Framework using the wrong database?
The Not So Thrilling Simple Solution
I pursued a number of different routes looking for the solution to this issue. In the end the solution is so simple. The wrong startup project was selected. That’s it. In Visual Studio 2015 I was using a different startup project. In Visual Studio 2017 I never setup a startup project and so one was selected automatically.
As it turns out Entity Framework pulls meaningful information (like database connection information) out of the startup project. The fact that I had the wrong startup project selected in Visual Studio 2017 was the reason why my Entity Framework Update-Database commands were not working the way I expected.
So, lesson learned, if you are experiencing issues with Entity Framework then check your startup project. It could be that you have the wrong startup project selected 🙂
I’ve recently begun working with Angular and by extension Angular UI-Router. The fact that you are reading this means that you likely have as well. That said, let’s all pause for a moment and cry together. I know it’s hard. You will get through it. It will be ok. We can do this.
Basic ui-sref-active Usage
One of the things that UI-Router gives you is the ability to add a class to an element if that elements state is currently active. This is done via the ui-sref-active directive.
So above we have some basic navigation with two states. The home state and the notHome state. The ui-sref-active directive takes care of adding the active class to whichever li contains the state that is currently active.
The Problem with Abstract States
The problem is that the ui-sref-active directive does not work correctly (or as we expect) when the parent state is an abstract state.
Let’s say you want to expand your “home” state a bit. Maybe you want to add a “dashboard” state and from there link to a “messages” state. You might set up your $stateProvider a bit like this.
You’ll see we’ve setup home as an abstract view. By default we want to land on our home.dashboard state. We also want ui-sref-active to set the active class on our “Home” link regardless of which child state we are on.
You will notice that in the code above we are now using ui-sref to link to home.dashboard. This is where the problem with ui-sref-active crops up, it will only show the active class if the state is home.dashboard. We want the active class to appear on any child of the “home” state. As it is, the ui-sref-active directive will not detect home.messages as active. So the question becomes, “how can we fix ui-sref-active so that it detects a parent abstract state”?
Tom informs us that there is an undocumented built in solution to this ui-sref-active problem. The solution, he says, is to “use an object (like with ng-class) and it will work”.
Code examples that Tom provides:
<!-- This will not work -->
<li ui-sref-active="active">
<a ui-sref="admin.users">Administration Panel</a>
</li>
<!-- This will work -->
<li ui-sref-active="{ 'active': 'admin' }">
<a ui-sref="admin.users">Administration Panel</a>
</li>
That’s it. Now we can link to children of abstract ui-router states and ui-sref-active will behave the way we expect it should.
It’s been about seven months since I setup a Wireless GitLab server. Since then I’ve figured out how to list updatable packages on Ubuntu Server. I’ve also performed several updates using sudo apt-get update && sudo apt-get upgrade.
gzip: stdout: No space left on device
Today I ran into a new problem. Upon trying to perform an update I was presented with a peculiar error. It said gzip: stdout: No space left on device and it told me to run apt-get -f install to fix things up. So… that’s what I tried doing. I tried running the apt-get -f install command but to no avail. The command would not complete successfully.
This is about the time when I start getting really annoyed with Linux and the command line and all the things associated with configuring things manually like do I really need to download the entirety of the Linux MAN files inside my HEAD? DO I NEED TO DO THAT? GAHasldkjsadljfsadfsdsdf!!!!
Calm yourself.
The /boot partition is 100% full
Ok, so it turns out that the apt-get process can fail if the /boot partition becomes 100% full. There were a number of suggestions online that indicated you needed to clean out the /boot partition by removing old linux-images that you don’t need anymore. Many of these suggestions involved using sudo apt-get remove [package-name] or using sudo apt-get autoremove which are both completely valid options… IF APT-GET WERE WORKING. But apt-get is not working, that’s the problem.
So… I Googled a lot and dug through a lot of forums. Finally I stumbled on this uber helpful answer on askUbuntu. I’ll go ahead and paraphrase the answer below so that I can easily find it again. Yes. This is all about me.
Cleaning up the /boot partition
In the case where your /boot partition becomes totally full you can use these steps to clean it up. (From flickerfly on AskUbuntu).
Run the following command to get a list of the linux-image files that you don’t need anymore.
Create a command to remove the folders you don’t need anymore. You can do that with a command like this (where brace-expansion is used to save keystrokes). Use the output from the command above to build your command.
EXAMPLE
sudo rm -rf /boot/*-3.2.0-{23,45,49,51,52,53,54,55}-*
Now that apt-get has space to work with you can actually run sudo apt-get -f install to clean things up.
Use Purge to manually resolve issues with “Internal Errors” (if you get any internal errors).
EXAMPLE
sudo apt-get purge linux-image-3.2.0-56-generic
Run `sudo apt-get autoremove ` to clean up anything orphaned by the manual clean.
Now you can finally proceed with those updates you were wanting to do.